
Experimental design is gaining popularity in business, and this article compares two common types of experiments in marketing: incrementally measurement against a holdout group and A/B testing.
What is a controlled experiment?
A controlled experiment is an experiment where the results of two or more representative groups are compared to determine which treatment produces better outcomes. One of the groups is often called a control group. This group represents business as usual or lack of special treatment.
A/B tests and holdout experiments use the controlled experiment framework, but they measure different things.
A/B testing is a special case of experimental design aimed at determining a better-performing version of marketing communication. In an A/B test, all targets get randomly assigned to a group that gets exposure to the corresponding treatment. Either group A or B can be called control.
Holdout group is a type of control group that is being completely held out of a marketing treatment.
The difference between holdout measurement and A/B test is in what we are measuring. In holdout testing, we measure the absolute effectiveness of the communication. A/B test measures the relative effectiveness of option A vs option B of the communication.
Holdout experiments are used for incrementality measurement. They measure the incremental impact of additional marketing dollars.
To be valid, both of these experiments need to comply with the same design principles as regular test vs control design.
When is it appropriate to use A/B tests and not holdout measurement?
The most common case when A/B tests should be used is when we cannot withhold treatment from our target audience. For example, if we would like to test different marketing messages on the landing page of a website, we have to use the A/B test since not having a landing page is simply not an option. The A/B tests are very popular in digital/web analytics for precisely that reason – while it is easy to test different versions, it is not appropriate to withhold the treatment altogether.
Another common use case of A/B testing is when withholding the treatment is unethical. For example, it is a standard in cancer research for new drugs and protocols to be tested against the standard treatment protocol. If the new drug or protocol provides advantages, it will be recommended over the standard course of treatment.
What are some common holdout tests?
Measuring against a holdout group is common for individually targeted campaigns, such as direct mail and email. In this case, a holdout simply does not get the targeted promotion, and their purchase rate is compared to that of the treated group.
Some companies are able to conduct holdout tests on non-individualized communications such as display and search ads. Tracking the outcomes from the treated and holdout group may present a challenge in this case, and that’s why these tests often need a large scale to be valid.
Can I combine the advantages of A/B testing and holdout methodologies?
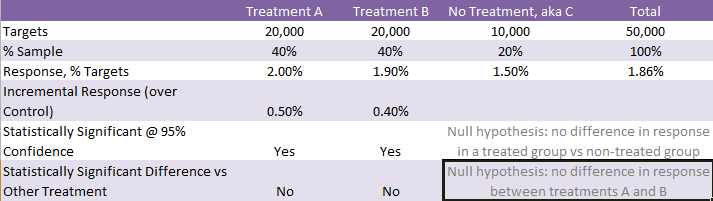
It is certainly possible, and I call it A/B + Holdout testing. The setup of this experiment is pretty simple. You need to split your targeted group three ways: the first group gets treatment A, the second group gets treatment B, and the third group gets no treatment.
This setup allows you to measure the absolute effectiveness of marketing communications and compare the effectiveness of A vs B all in one test. This is a very powerful approach, and if you have the sample size to run tests this way, I would certainly recommend doing so.
Sample A/B + Holdout setup:
What are the most common problems with controlled experiments?
From my experience, there are a few common ways to invalidate the results of control experiments.
Insufficient sample size
I have been lucky to work for big consumer companies, so the sample size is usually not an issue. My general guide is if you are looking for small response rates (around 2%) typical of marketing, and your “meaningful” cut off for the difference is in 0.3%-0.5% range, you need at least 10,000 targets in your smallest group. 20,000 is usually better.
Please note that it is your smallest group size that drives the significance, so if you decided to go with 1,000 targets in your alternative treatment group, it really does not make much difference whether your main group is 10,000 or 1,000,000. Conclusion: To improve the statistical power of your results, beef up your smallest group.
You can refer to a independent two-sample t-test formula to calculate your required sample size given your expected response rate and a difference/lift you need to produce. If you prefer to use an online sample size calculator, this article gives an explanation of how to do it.
Testing communications for different customer segments without exposing customers of the same segment to all treatments.
This happens when marketers try to tailor communications to the customer segments, and in the process forget that the point of testing is to prove that tailored communication works better than a generic one for the same segment.
For example, if you are customizing your communication for customers with no kids and for customers with kids, then to prove that the kid-friendly version B of your communication works better than generic/adult-only version A, you need to expose your segment of customers with kids to both versions A and B, and then compare the outcomes.
If you expose them just to their targeted version B, you will not know if an increased response of this segment is the result of this segment being better targets in general, or it was your customization that made the difference.
Here is an example of an incorrect A/B + Holdout test design for two customer segments:

This test design will be able to tell the absolute impact of communication A on Segment 1, but it will not be able to tell if communication A or B works better for Segment 1, thus losing the comparative insight that A/B testing provides.
Below is an example of a correct setup for the A/B + Control test for two segments:

The design above will be able to show whether treatment A or B is better for Segment 1, and the same for Segment 2. It will also be able to measure the overall effectiveness of both treatments for each segment, thus providing full and complete information to the marketer on how to proceed forward.
Not looking at the bottom line.
The end goal of marketing is to produce sales. While increasing clicks or calls is important, it is not going to help the company improve the results if the clicks and calls don’t translate into purchases.
I have seen many cases in both the analog and the digital world when an increase in walk-ins, calls, and clicks never translated into sales. A good analyst should always keep this in mind.
It also helps us take our minds off treatment-specific behavior and look for ways to assess its overall impact: oftentimes intermediary KPIs are not available for the control group, while the bottom line sales are.
Not testing on a representative sample of customers.
This last mistake is often made by the digital marketers, who sometimes stop the test before it has run its course over a full “natural” customer cycle, like a full week.
While there are some tests that are specifically designed to run during a specific time, for instance, testing Holiday communications around Holidays, in the most general case, you want to run your experiment for at least a full week.
Sweating the small stuff while forgetting about the big picture.
When choosing your best in-market tactics, you should always test the big stuff first.
For example, in direct marketing, mail/email frequency is more important to figure out than the color of a design element or copy of the offer. Creating a testing plan that tests the most influential variables first will help you optimize your marketing efforts faster and with better results.
Don’t be afraid to make bold moves, like stop certain types of marketing for an extensive period of time, or radically simplify checkout. These are the things that you should expect to yield the most for your testing buck.
Another downside of the strategy of trying to test everything, from target segment to offer to copy to color, is that it leads to small sample sizes. As a result, most tests won’t show statistically significant differences – or worse, you may find some false positives.
Not accepting inconclusive results of A/B testing.
Often, the results of the test are inconclusive or the difference is small. This is when statisticians say that the null hypothesis can’t be ruled out, and it is still a valid result of the test that marketers need to accept.
Not every small change produces a big shift in behavior. In fact, the vast majority of A/B tests that I have analyzed in direct mail failed to deliver any difference.
Using A/B test to create an impression of scientific testing activity.
This is my pet peeve. I always suspect this situation when it is possible to use control groups along with A/B test, but it is not done.
From my experience, the total difference that direct mail and email produces on customer behavior is small, so honest marketers have to admit that their programs are not paying for themselves and redirect their budgets to more effective communications.
However, many choose to cover up the overall ineffectiveness by creating a pseudo-scientific program of extensive A/B testing. They create tests of small changes in marketing materials, and these changes produce little difference. This last mistake of the testing incorporates many other mistakes – from sweating the small stuff and ignoring the big picture to the inability to accept that the small changes don’t improve the results.
Summary of A/B testing recommendations:
- A/B test does not measure the absolute effectiveness of communications
- These tests are popular in digital marketing
- A/B test is a type of experiment, and it should comply with the same principles as test vs control methodology
- A/B test is justified when true control is impossible or unethical
- If possible, always use A/B + Control testing
- Incorporate sales/profits into your outcome measures
- When testing to find the best versions for a segment, always test all versions on that segment
- Make sure you have at least 10,000 targets in your smallest group
- If running “live” digital tests, allocate at least a week
- Accept that versioning rarely produces a big swing, so A/B tests are often inconclusive
- Don’t sweat the small stuff
- Don’t abuse A/B tests to cover up ineffective communications